

Erasure Coding (EC) and Information Lifecycle Management (ILM) aren’t unique to StorageGRID. They’re ubiquitous to the object storage landscape, underpinning concepts like RAID and compression. Yet if you’re unfamiliar with the architecture these concepts might be confusing at first glance. The hope with this post is to cover these concepts, not only in direct relation to StorageGRID, but in a way that can apply globally.
A Quick Intro to Object Storage
Objects are a data storage methodology going back several decades. The general idea is instead of creating and maintaining a hierarchical file system the file/chunk of data/block is packaged up by an object, passed to an object provider, and the provider does all the heavy lifting (protection, distribution, servicing, etc). The system that created the object just hands it over and asks for it back via an addressable ID.
One of the great things about object is that the data is globally placeable and retrievable. The analogy I always hear, and use, likens things to leaving your car at an airport. In a traditional file system you take your car and park it yourself. You have to keep record of what garage it’s in, what floor, what spot. If you need your car you need to remember where you left it. Object storage is like a valet. You drop your car off and get an ID. No mater where you fly to you can provide that ticket and the valet will bring your car.
Object storage has ballooned in the modern age alongside unstructured data and the need to provide global content services. Like any other service there are multiple protocols out there with, at least in my experience, AWS S3 being the most common. A large portion of the protocol is command sets for object processing objects (eg. PUT and GET).
Now I have vastly oversimplified how this all works. Hopefully enough to clarify without being over pedantic. I’ll throw some links at the bottom of this article for further reading.
NetApp StorageGRID
StorageGRID is NetApp’s primary solution for on-premises object storage. At some point it was (or still is?) called StorageGRID Webscale. It’s a software solution that can be installed on VMs and general servers but is most often sold with hardware from NetApp. All components, whether virtual or physical, form a global object namespace capable of geo scaling in the hundreds of PBs. It predominantly supports the S3 object protocol, but also has support for OpenStack Swift.
Note that ONTAP can also serve as an object endpoint (S3) but, as of this publication, doesn’t have any any of these general object management capabilities.
Erasure Coding (EC)
Once again I’m going to gloss over a whole level of history and complexity and simplify a bit. Erasure Coding, from the perspective of StorageGRID, is the process of taking an object, breaking it out into individual fragments, and creating additional parity fragments.
Erasure Coding comes in different schemes represented as K+M where K is the number of data fragments and M is the number of parity fragments. One of the most common EC schemes I see in the field is 2+1. Two data fragments, and one parity fragment. Allow me to illustrate…
In EC 2+1 an object comes into the environment and is split into three fragments. Two general data fragments (K, A & B) and one parity fragment (M, P1). Three fragments over all.
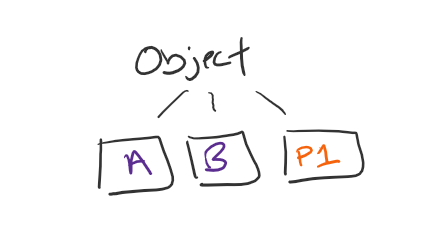
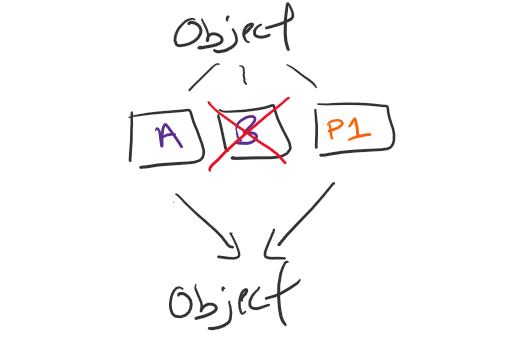
Those three fragments can be distributed anywhere across the environment. Best practice is at least on three individual SG data nodes but it could also be three separate data centers. What happens if something happens to one of those data nodes or sites? With EC you only need K number of fragments to reconstitute. In this example, EC 2+1, means I only need two..
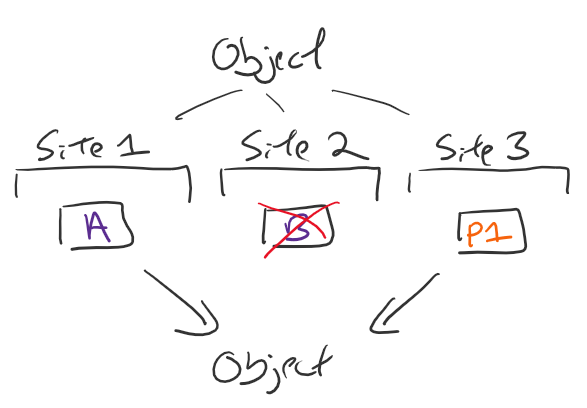
Those object fragments could all be at one site, or distributed across multiple,
There are multiple erasure coding schemes with a different amount of fragments that all work in the same way. Consider EC 6+2…
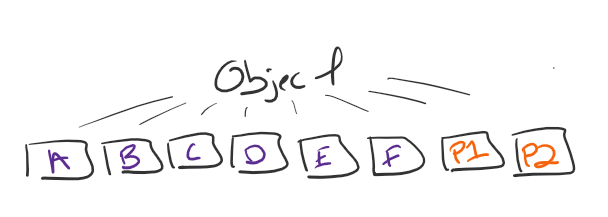
As long as I have 6 fragments available I can reconstitute that object.
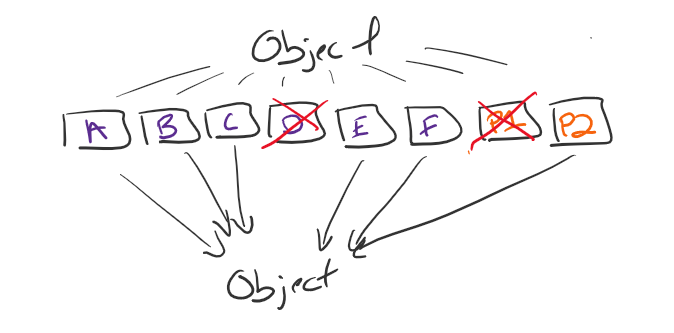
So, what’s the point? Massive data availability and durability.
StorageGRID appliances from NetApp already have high available RAID protecting the content at the drive level, but there are scenarios where an entire node might go offline. Or, if you’re running the StorageGRID software on hardware you provide, there may or may not be any sort of resiliency built in. Distributing objects across multiple nodes builds in data available and durability. Up to and over 15 nines of resiliency (99.9999999999999%).
Oh, and before I forget, there is overhead when doing EC. When an object is ingested the system, calculates parity, breaks it into fragments, then writes it across multiple locations. Reverse when reading an object out. Replicating an object, see the next section, will provide better response times. Same also applies if you kick of a large change to an EC policy causing the StorageGRID to go back and rebuild all object fragments.
Slight detour down the road of replication and overhead
I need to take a few minutes here to talk about erasure coding overhead and data replication. StorageGRID is one of the most scalable systems I’ve ever encountered. You could have have data measured in TB, or PB, and that could be either at a single site or distributed globally. To protect that data can do EC, or you can do simple replication.
Replication is just creating additional copies of an object. One copy here, one copy there. It could be at one site, two sites, etc. The only downside to object replication is that it’s essentially 100% data overhead. If you have 50 TB of objects, and you replicate them, you need to have 100 TB of capacity.
Erasure coding also has overhead, but less. EC2+1 has 50% overhead. EC 6+2 about 33% overhead. One way to think of it is object replication is creating a 100% parity, where as EC is only creating parity for a subset of the data.
Replication is the go-to for a couple of scenarios. If you have objects that absolutely need that data protection, and capacity overhead of no consequence, then replicate. Straight replication is also the most efficiency way in a simple two-site configuration. It’s also more efficient to do replication for objects 200KB and smaller (the metadata and compute requirements reduce the value of EC).
Information Lifecycle Management (ILM)
In a StorageGRID infrastructure, Information Lifecycle Management (ILM), is simply a set of policies on how to treat objects over that object’s lifecycle. Where to store it, how to store it, how long to store it, etc.
One of the great things about objects is the ability to create metadata tags. Let’s say you’re building out a data lake based on candy. One subset of that data is images of the wrappers. Each image becomes an object with associated meta tags. Type of candy, colour of wrapper, size, etc etc. You can apply ILM policies against any of those tags.
Better yet, you can layer and transition between policies. November rolls around and you don’t need a high availability SLA for candy with the “Halloween” tag? Use an ILM policy to move that to a slower disk pool, transition to an EC scheme with less overhead. Don’t care about data that’s three years old? Automatically delete it.
StorageGRID In Practice: Erasure Coding
Erasure coding schemes are created and applied to a specific storage pool. This is done in the GUI under ILM > Erasure Coding. Depending on on how many many nodes are available in the pool StorageGRID will limit/recommend the available EC schemes.
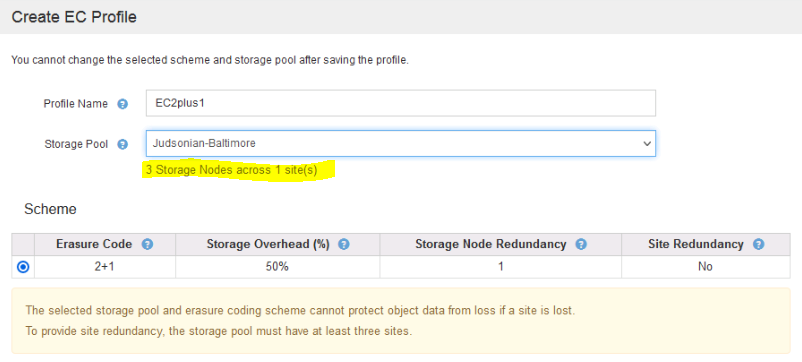
The above example is a single site with only three storage nodes so I’m limited to my EC options. The below is when I have a storage pool with nine nodes across multiple sites. Note how each provides info on overhead and node redundancy.
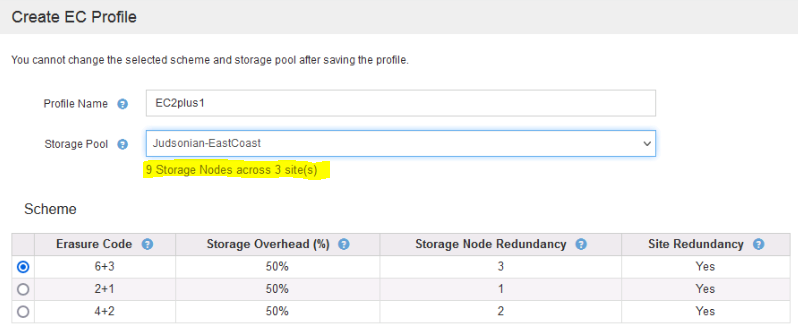
Best practice is to always have N+1 nodes in your environment, where N is the total of the EC scheme. For example, if I’m going to use EC 2+1, I should have a minimum of four nodes. The extra node is to ensure continued EC compliance in case one of those nodes is down. Since I need three nodes for EC 2+1 in a four node environment I will still be able to maintain the EC 2+1 SLA if one is offline. If you don’t have enough nodes it will still create the parity but multiple fragments will reside on the same node. If you don’t have enough nodes EC won’t be able to process and the object will remain in the dual commit stage and a EC backup will occur.
StorageGRID In Practice: Information Lifecycle Management
To implement an ILM policy, you must first create an ILM rule under ILM > Rules. Here you’ll create, as the name suggest, a rule with various object handling procedures.
First step is creating a rule.
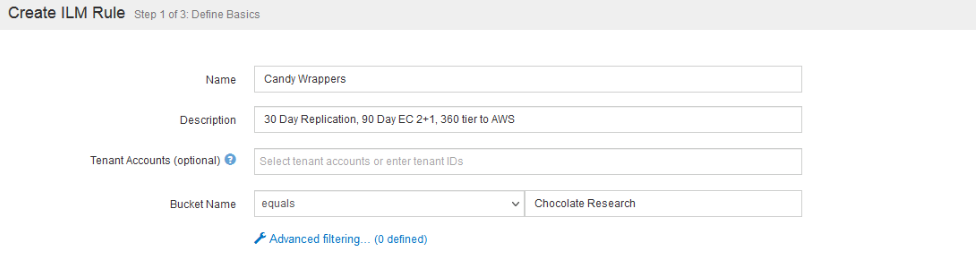
A couple of things to note in the above step. First is the bucket name. You can create a policy that applies to all or a subset of buckets. If you limit the bucket options here you’ll have limitations on how you can apply the policy later on (in other words you can’t have a apply a policy that is limited to a specific bucket globally without a default ILM policy, you know, for all the buckets with a different name).
If you clicked into “Advanced filtering…” you’ll be able to provide advanced filters (thus the name) and configure the policy to apply to those metadata tags.
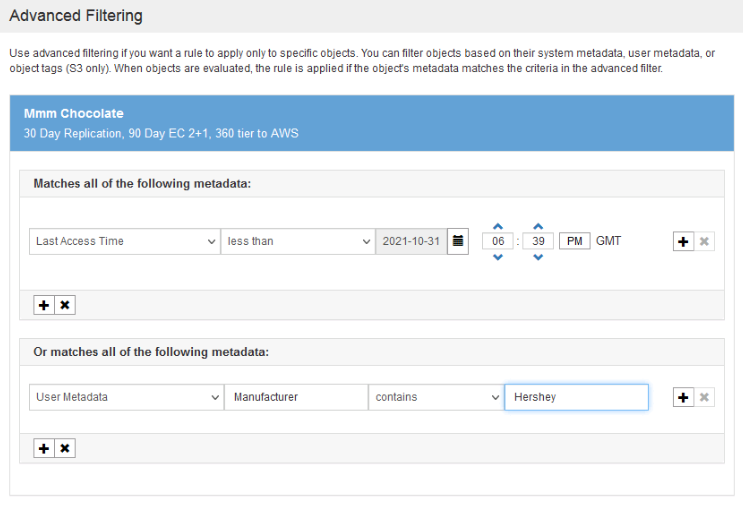
Next up you need to create each step in the rule…
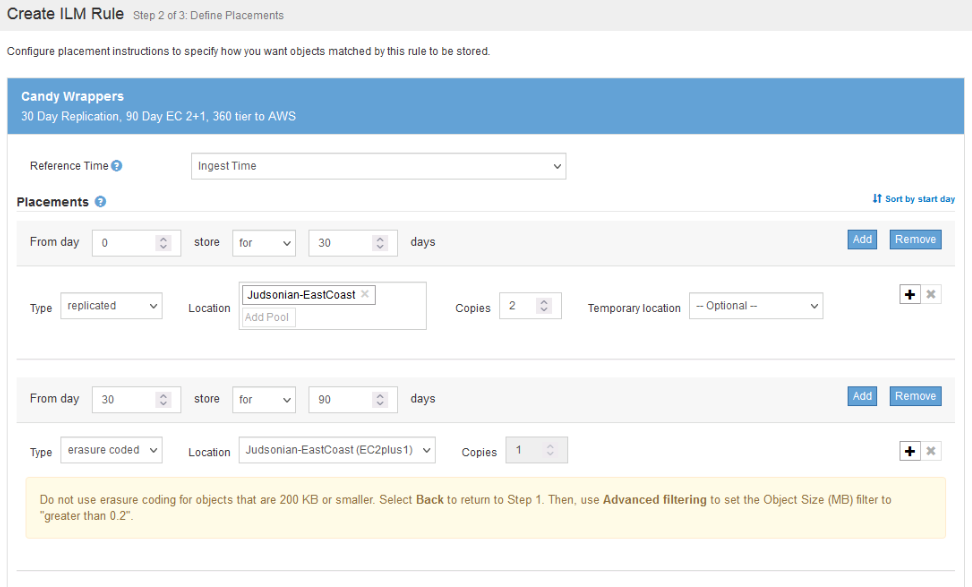
In the above example I’m saying from ingest (day 0) replicate that object with two copies for 30 days. From day 30 transition that object to a EC 2+1 scheme.
I can add additional lifecycle steps such as moving that data up to Amazon S3.

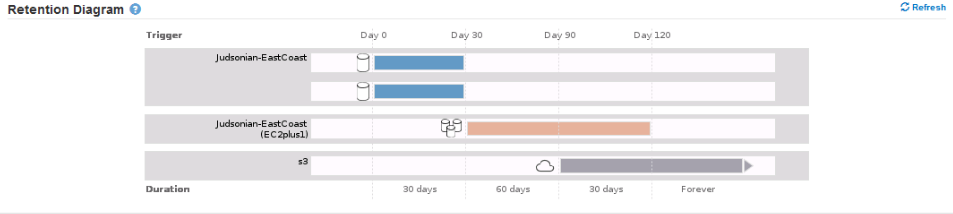
There’s a great graph at the bottom that visualizes the lifecycle of the policy buuuuuut you need to click refresh to apply the policies to the diagram. Unfortunately (as of version 11.5) it doesn’t update automatically inline.
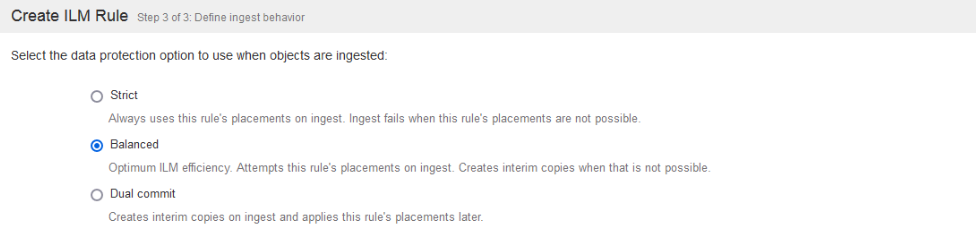
Last step of this process is determining how aggressive the ILM policy is. If part of the policy is to make multiple copies of an object, or apply EC, StorageGRID will attempt to do that up front. There are various ways it could fail, such as network outages to partner sites. Default is a balanced approach were SG will attempt to apply ILM at time if ingest, but if it can’t complete, then place two copies of the object where possible and come back later.
Ackchyually, there is one more step, and that’s to take your ILM rules and apply it to a policy. You can do this under ILM > Policy.
Creating a policy is just the application of your ILM rules. You first start by creating a policy then go back and ether simulate or active.
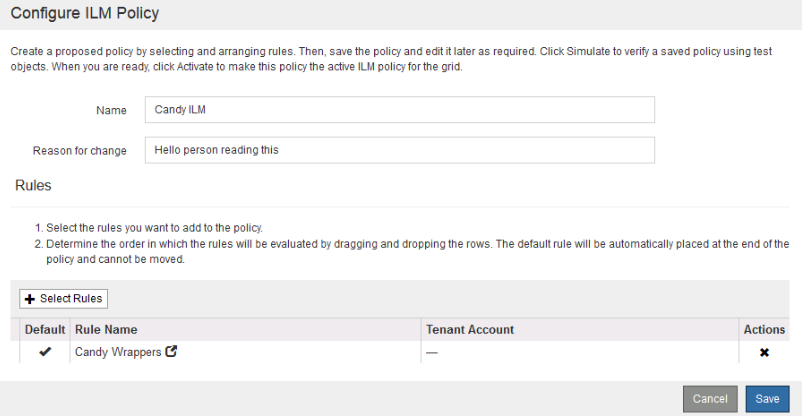
The idea is to make sure you take your time and implement the proper policy changes. If you go and create a policy that removes object, well, those objects are going to be removed without a way back. Thus, simulation and warning screens help you tread carefully.
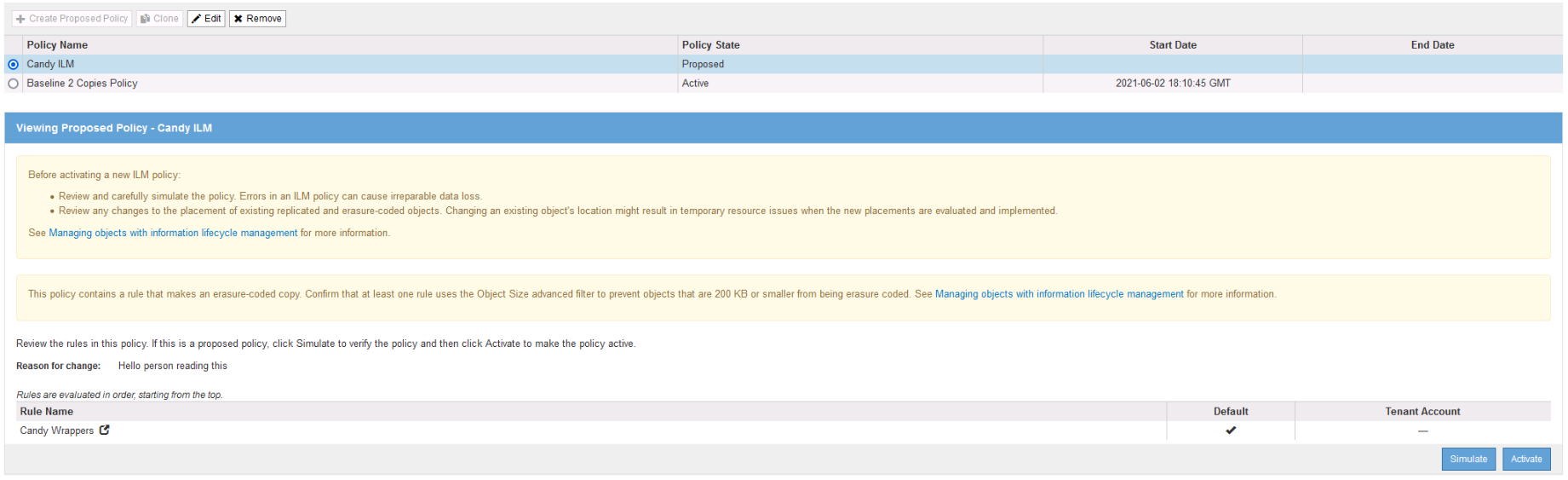
It’s important to note that you can change ILM policies at any point. However, doing so will cause the system to go through and reevaluate/distribute/fragment/etc depending on the changes. If you have a lot of object, and a busy Grid, then things could get overloaded. In this scenario it’s recommended to open a ticket with support ahead time – they can help you track the workload and throttle as necessary. But hey, you planed for your ILM before you started doing ingest… right? Right
In Conclusion
At first exposure the paradigm of object storage, and how to manage objects, can be a confusing one. But if you’re like me, once you wrap your head around some of the core concepts, it all falls into place.
Additional Reference
- What is Object Storage? A Definition and Review (nice blog that covers object better than I did)
- StorageGRID documentation on erasure coding (explanation and available schemes)
- Wikipedia: Erasure Coding (for you nerds)
- Creating ILM Rules in StorageGRID (quick video from NetApp)
Article History
- 3/29/22 – Initial Posting
- 4/18/22 – Fixed the bit about what happens with EC when not enough local destinations are available