

Before I go further it’s best to have an understanding of object storage. The analogy I hear quite a bit, and now tell myself, equates object storage to valet parking. Well, magical valet parking. Using traditional file storage is like using your average self park lot. You find a place to put your car, you put it there, and you’re responsible to remembering where you parked it and retrieving it for later. Object storage comparatively like valet parking. You drop your file off, get a ticket, and use that as a reference to for the valet to find the file for you later on. Best part is that you don’t have to be where you dropped the file off. Any valet station you stop at, be it in Washington DC or San Francisco, the valet can take that ticket and retrieve your file.
When you place a file in a traditional file share, you have to pick the directory paty (hieratical location) and keep track. Placing a file into an object store gives you an object ID, and the object storage environment is responsible for placing, keeping track, and retrieving the object. This lets applications be a lot less hands off with file protection and maintenance. The object store environment can handle protection of the file by creating copies, aging of the object by moving it around based on access, and even replication by making sure that the object exists in multiple places at the same time.
While object storage has been around for quite awhile, the rise of hyperscalers like Amazon and their S3 object store have really brought a new attention to the architecture. This is largely in part due to the dynamic and exponential growth of data, and it’s requirement for availability, in this day and age. This has lead to tons of vendors now supporting some sort of object store integration. Because of Amazon’s gorilla-in-the-room status this often centers around S3 specifically.
Now as easy as it is for someone to set up a S3 bucket and start dumping data to it, what if you don’t want to go to the public cloud? Financially it can be burdensome and there’s something to be said for keeping data close and in house, especially when it can be potentially sensitive. I’m not saying S3 isn’t safe when properly secured, but there’s a warm and fuzzy feeling you get from keeping data close by that seems to appease constituents and shareholders. This is where NetApp StorageGRID comes into play.
StorageGRID is a hyper-scalable object store that you can build and maintain in house. Like the big cloud providers StorageGRID can go as big as you dare go. We’re talking big, with a capital BIG. Big, like 100 billion objects and 140 petabytes BIG. All this behind a single name space and load balancing to provide the best availability and distribution.
It does all this by while protecting data. The simplest way to just to configure copies of your data.. You can configure to have a copy on one of the nodes or have multiple copies of your data that live on different nodes in your SG. Or you have the option to use erasure coding!
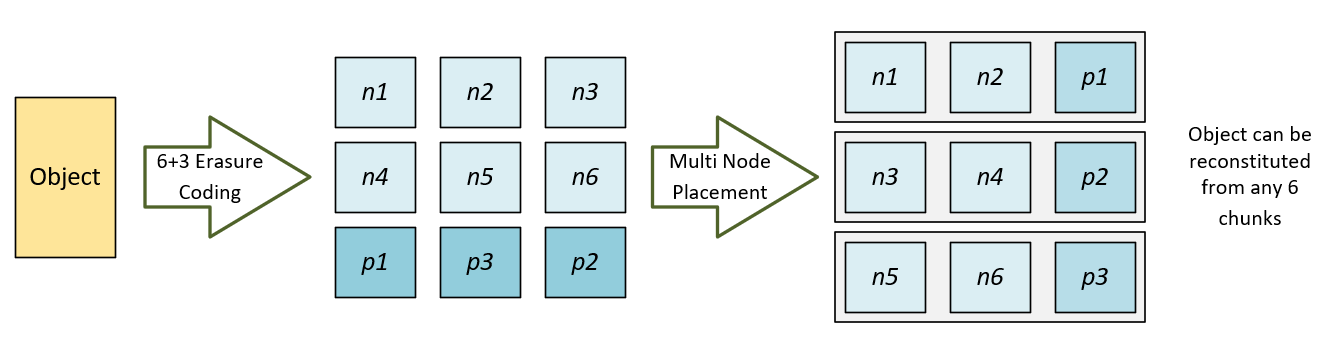
When you have objects erasure coding breaks them down into smaller segments and distributes them across multiple nodes and/or regions. There are different coding schemes marked as X+Y, where X is the number of segments each object is broken into, and Y the number of additional parity segments. X is also the number of segments you need to build an object should something bad happen along the way.
For example, you’ve got an object protected with 6+3 erasure coding. That object is consists of 9 different pieces floating around the StorageGRID environment, and any 6 portions is enough to constitute the object. If you have 3 StorageGRID nodes you can pull your object out even if one takes a dump.
You take replication, pair that with erasure coding, and you’re taking data availability in the 10 to 15 9’s range. 99.9999999999999% uptime sounds good, right?
Also available is object compression, encryption (AES-128 or AWS-256), hasing to verify object integrity, and WORM. WORM? Write Once, Read Many. If you have compliance or strict data security rules you can ensure that any data written to StorageGRID won’t be overwritten or otherwise messed with.
Okay, so I can grow really big, and I can safeguard my data, but what am I going to use with the environment? The use cases are pretty much endless. Pretty much every new big application is going to use object store for data creation and storage. Want to build out the next big streaming service? You’re not gonna be able to service thousands of customers when those Celine Dion tracks are sitting in a centeralied NAS share.
StorageGRID is perfect for backups too. Short term, and long term tape replacement. When you send those backups out to tape you hope, fingers crossed, that if a terrible day ever comes you’ll be able to read that data off. With StorageGRID you know that those long term backups are being safely and cost effectively stored.
There are so many integration points because StorageGRID uses your the S3 and Swift object protocol standards. Because of AWS’s gorilla status everyone wants to write to their Cantemo/Videspine, object store. And because we support S3, we support those apps too. Talking Veeam, CommVault, Rubrik, Veritas, PoINT Systems, Data Dynamics, Cetra, Citrix, OpenText, etc. StorageGRID even integrates with Glance, Swift, Cinder, and Keystone in OpenStack.
Have an application that doesn’t have a object integration point? Well there’s a NAS Gateway for that. Simply deploy one and you’ve got a way to translate CIFS/NFS into object. Performance may vary by deployment and workload, but it’s great when you want to get as many different applications making use of an investment.
But, after all this I’m burying the lead for existing NetApp AFF customers. FabricPool, the built in ONTAP tech that lets you tier cold data to object store, integrates perfect with StorageGRID. It’s a great way to drive TCO down when you have a bunch of static datasets.
To wrap things up, combine everything I just raved on about. Top tier data protection and availability. Mind boggling scalability. Application and use cases across every business practice. Centralize everything into your own on premise cloud while lowering TCO. What’s not to love?