
I initially started writing this blog as an introduction and explanation of Cloud Backup Service by itself. I quickly realized that you can’t really understand Cloud Backup without talking about the SnapMirror to Cloud functionality now available in ONTAP 9.8. Bear with me and you’ll see what I mean.
Oh, and for the sake of (relative) simplicity I will try and use full terms for each of the components I’m talking about. Though I may refer to Cloud Volumes ONTAP as CVO here and there. It’s bad enough that there’s multiple terms for the same functionality without adding “CBS” “SM2C” “C2C” “S2C” or “B2C” to the mix like someone threw a bowl of Alphabets at the wall.
SnapMirror Cloud
SnapMirror to Cloud is functionality new to ONTAP 9.8 (well, it may have been there in 9.7P5, more on that later) which simply allows for SnapMirror to target object stores.
That’s basically all you need to know but I’d be lax if I didn’t go into a bit more depth.
The ability to take snapshots and send them to an object repository is based on a pair of REST API functions within ONTAP. The first is SnapMirror Cloud which is basically just the core functionality that allows for the translation of the SnapMirror block dataset to an object format. The second is SnapDiff which allows for tracking of differences between Snapshot copies. In conjunction this will allow a snapshot to be taken, send to object storage, and subsequent incremental snapshots linked by a change lot. So, similar functionality to most backup solutions. You have an initial snapshot that’s a full, followed by incremental ones.
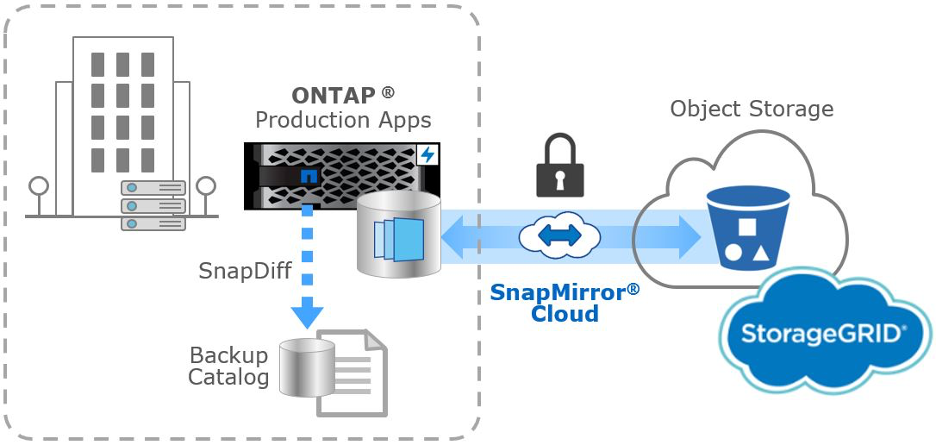
(Taken from this NetApp blog article)
Since this is new in ONTAP 9.8 there are some key limitations. As of this release only FlexVols are supported (no FlexGroup support) and there’s no support for MetroCluster or SVM-DR. There’s also no support for deep archive tiers (i.e. Glacier) but you have a wide range of object targets: AWS S3 & S3 IA, Azure Blob, and Google/GCP standard object.
Everything else operates just like normal Snapshots do within the ONTAP ecosystem. You maintain storage efficiencies and have the same full volume or file level restore features. Well, pursuant to the functionality of the application managing the data (e.g. they need to build in cataloging, granular restores, etc).
As of right now (Nov 2020) the APIs that power this aren’t user facing (nor is there any GUI/CLI support within ONTAP). In addition there are only three backup providers (as of Feb 2021) who offer that functionality, Cleondris, ProLion and Druva (I understand that CommVault is currently working on adding the integration). SnapMirror Cloud will have to be licensed through NetApp in addition to the backup provider’s licensing costs.
Yet similar functionality is offered through NetApp directly…
Cloud Backup Service
Cloud Backup Service is essentially the SnapMirror Cloud functionality built into ONTAP but orchestrated through Cloud Manager. Cloud Manager is NetApp’s online portal for management of Cloud Volumes ONTAP (CVO), Cloud Compliance, Global File Cache, Azure NetApp Files/Cloud Volumes Service, Spot Cloud Analyzer, and more.
Note that for whatever reason sometimes it’s referred to as Cloud Backup, Cloud Backup Service, and Backup to Cloud. I don’t understand this naming inconsistency.
The Cloud Backup Service is able to take FlexVols from Cloud Volumes ONTAP instances, and on-prem clusters, and back them up to a public cloud object provider.
Note that if you look at NetApp’s Cloud Backup Service page it only lists Cloud Volumes ONTAP as being a supported product. Yet if you make your way to the Cloud Backup Service section under the Cloud Manager documentation you’ll see that on-prem clusters are a supported source.
What makes Cloud Backup Service stand apart is that it’s a SaaS offering. It has its own license, BYOL or pay-as-you-go, which is based on the used capacity of the volume you’re backing up (license includes SnapMirror Cloud functionality). On top of that you’ll be paying for the object costs (ie you store 50 TB in AWS S3, you need to pay Amazon for that storage). In other words, if you have a 100 TB volume and you’re using 70 TB of capacity, your licensing fee will be for 70 TB. If your storage efficiency is 2:1 your storage cost will be for 35 TB (not including additional incremental).
Cloud Backup Service currently supports S3/S3 AI, Azure Blob Cold Tier, and Google Cloud Standard. The catch is, for any CVO system, you can only backup to the object provider on the same cloud. Thus, CVO in AWS can only back up to AWS S3. On-prem can target either S3 or Blob – no word on GCP support. On-prem storage via StorageGRID is on the roadmap for first half 2021. From a security perspective, data is encrypted in-flight with TLS 1.2 and at rest with AES-256.
Now, to me, this is more of a disaster recovery or archive technology from a practical level. As of right now there’s no ability to restore individual files, just whole volumes. It also has the same limitation of only supporting FlexVols. That’s not a big issue if you’re protecting a CVO instance, as the majority of CVO volumes are created by Cloud Manager which doesn’t support FlexGroups, but could be a show stopper for on-prem clusters. An even more critical limitation is that Cloud Backup Service can not restore volumes to an on-prem cluster, regardless of whether it’s the source or not. While there’s no way I’d ever use a “backup” solution that couldn’t restore to the source location, I see it as being a good fit for dumping data copies off site for independent retention or as a source for a disaster recovery plan.
Update! – Jan 29 2021 – As of Jan 11, 2021 cloud backup now supports single file restores via browsable file catalog, but only for Cloud Volumes ONTAP and on-prem ONTAP. As I understand it you restore individual files from on-prem backups back to on-prem volumes. I’ve also been told that volume level restores to on-prem systems is supposed to be available within the next month or two. No word on Azure or Google Cloud for these features.
How to use Cloud Backup Service
Getting started with Cloud Backup Service is pretty straight forward… assuming that you already have NetApp’s Cloud Manager set up and have either CVO instances or on-prem environments discovered.
Once you’re in Cloud Manager you’ll see a Backup menu option at the top of the page,
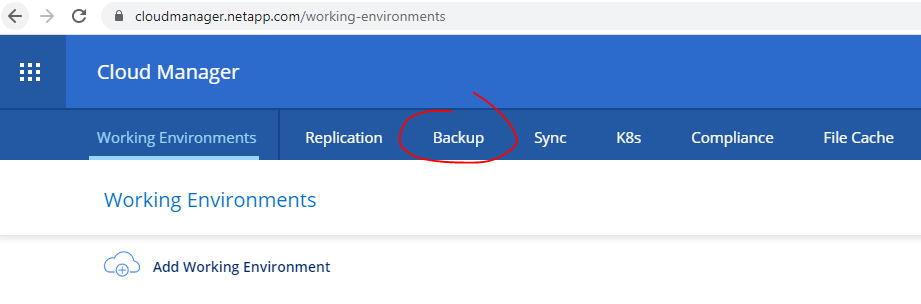
When you enter this section you’re taken to your Backup List. If this is your first time you’ll see a notice that there are no existing backups. Click Backup Settings up top and you’ll see all the volumes that Cloud Manager is aware of. To get started with a volume click Activate Backup.

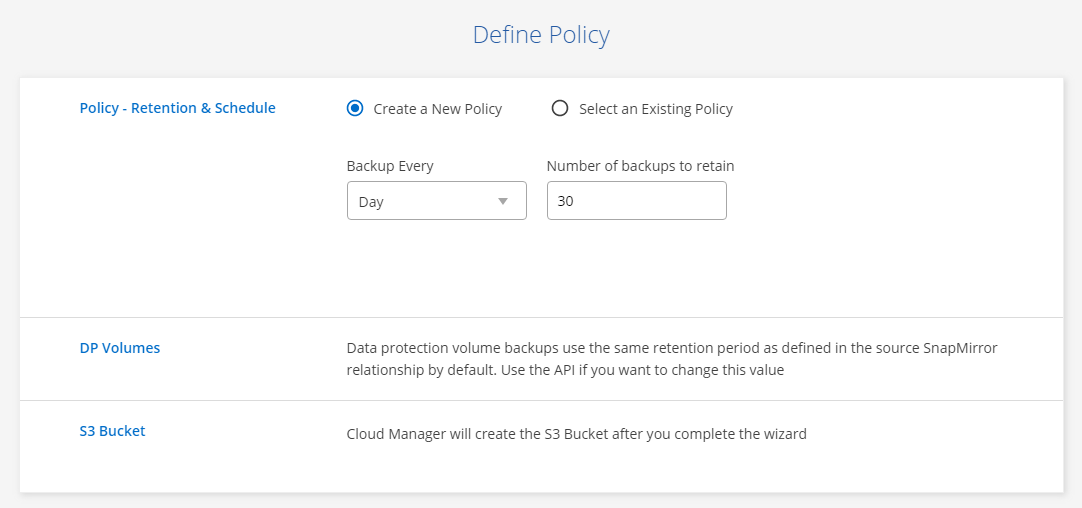
When you click in – it might take 10 seconds to load – you’ll get a two part wizard. Here you can create your retention and schedule settings if applicable. Data protection volumes (e.i. if the volume is a SnapMirror destination target) have to use the same retention period as the source SnapMirror configuration. If you want to change that you’ll have to dive into the API.
In my testing it looks like Cloud Manager creates the target bucket automatically. Once you complete the wizard you can go back in, modify the policy, and see what the bucket name is.
The second page of the wizard just allows you to check multiple additional volumes if this is your first time through.
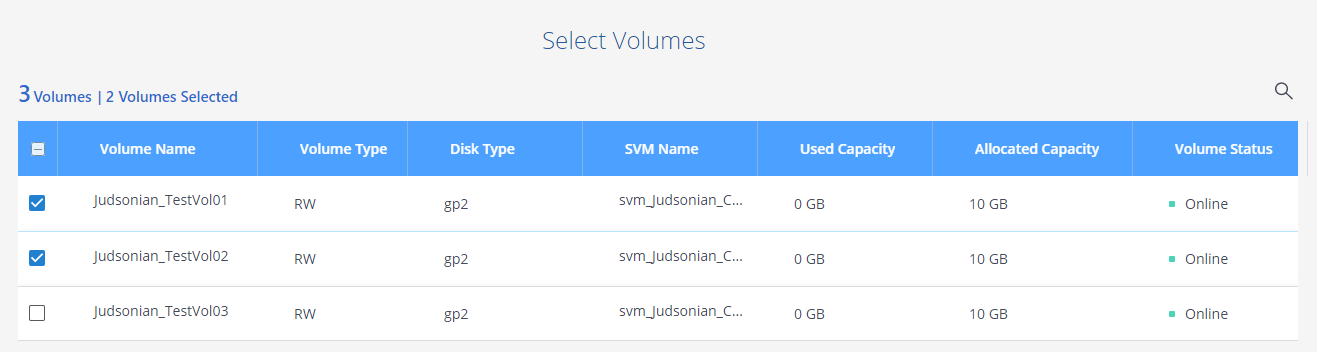
Once you’ve added volumes to the policy you’ll see the volume backups in the Backup List. For each volume you can click View Backup List and which takes you to a short restore wizard.
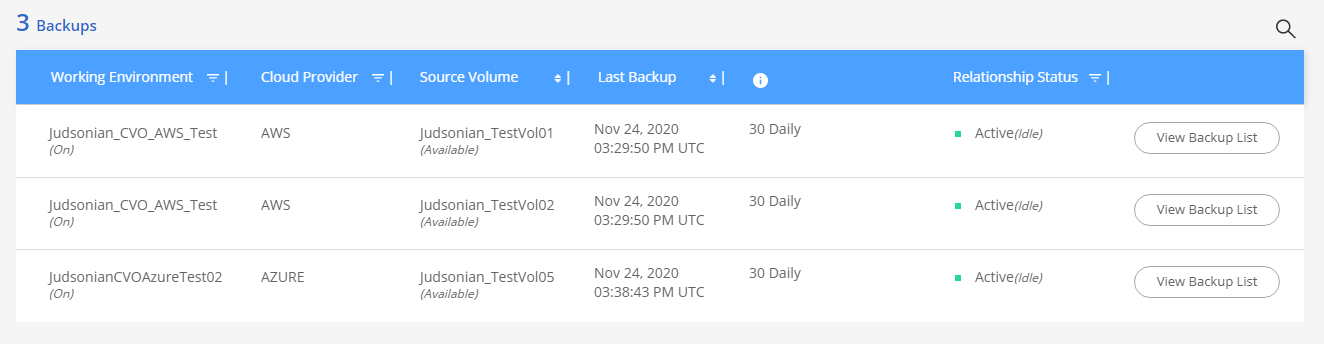
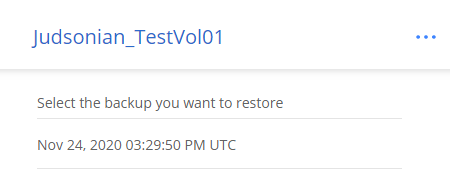
The restore wizard will allow you to choose the CVO working environment you want to restore to and the volume name.
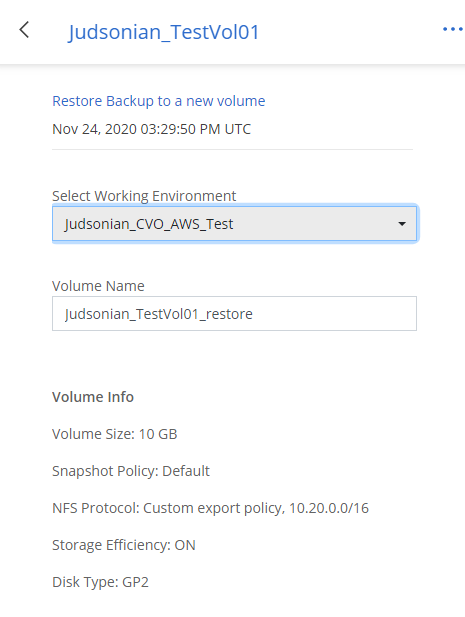
Here’s where things get interesting. The documentation for the restore process says “You can restore the data to a volume in the same working environment or to a different working environment that’s located in the same cloud account as the source working environment.” Emphasis mine. You would think, based on context, that this means the came Cloud Manager account. What it seems to really mean is cloud provider account. Which means, essentially, if you backup from an Azure CVO instance, you cannot restore to an AWS based CVO instance. In the restore wizard you’ll see a full list of CVO instances, but you can’t select non-applicable environments.
You also change seem to change the target disk type, or any of the other settings for that matter. I tried deleting a volume, then the associated aggregate. When restoring the volume it went as far as to create a new aggregate with that specific disk type.
Fun fact, when standing up a new CVO instance in AWS or Azure (GCP doesn’t have this same feature for whatever reason) you’ll be shown several SaaS offerings within the platform, including Backup to Cloud, which are enabled by default.
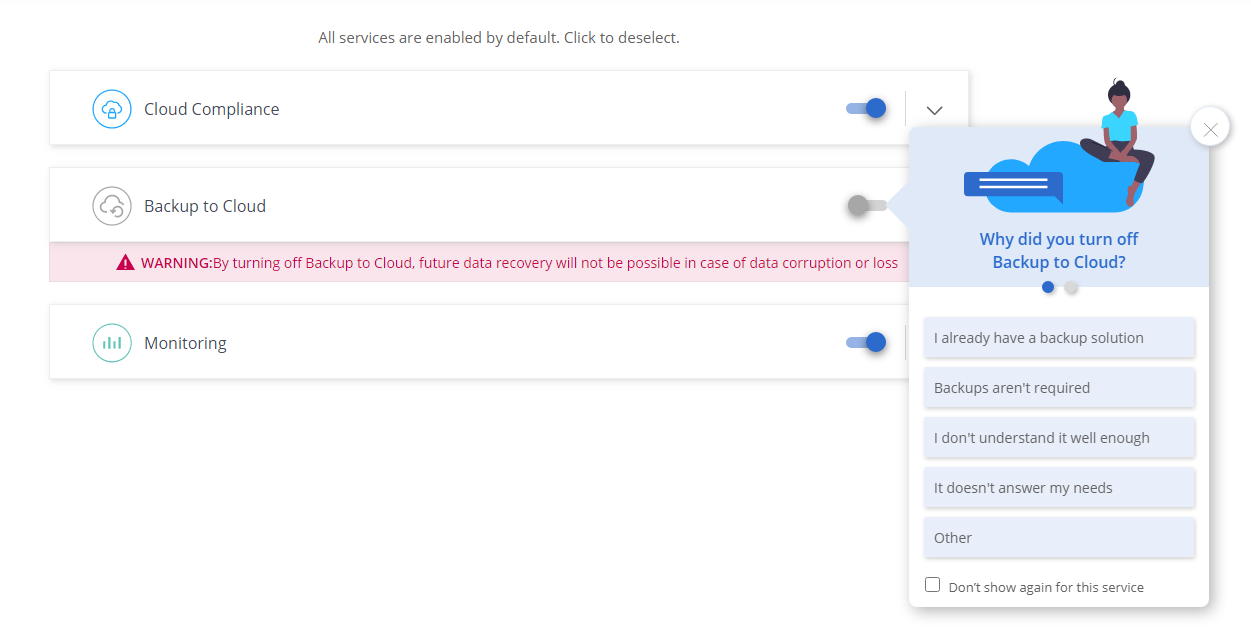
But wait, there’s more! And here’s where it gets wonky.
As mentioned, you have that screen pop up when setting up a CVO working envirnonment in AWS or Azure. But not GCP. But what if you want go back and enabled Backup to Cloud?
For AWS, you can click on the instance and Activate it. You can also go in to the Backup to Cloud backup settings and enabled it there.
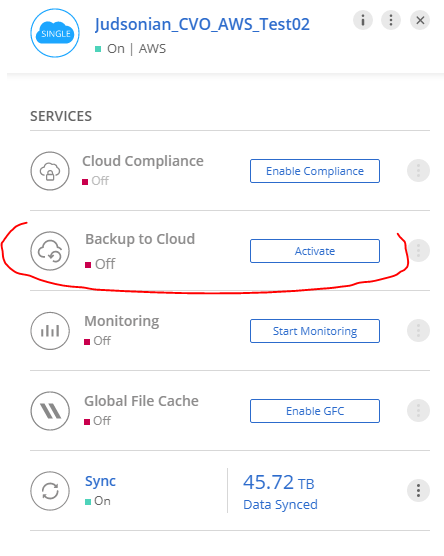
For GCP, you don’t have that top level option. You have to go into the backup settings and enabled it by enabling it on for a volume(s).
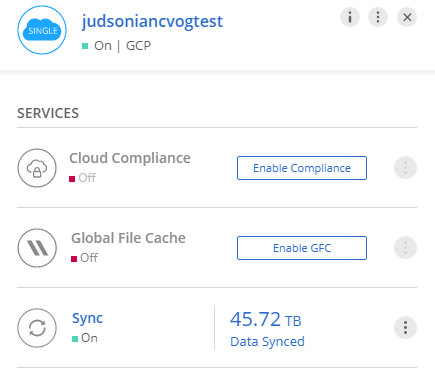

Azure, on the other hand, doesn’t have either option. Not only does the Backup to Cloud option not show up for the instance (like it does for AWS) but the volumes on that instance do not show up in the Backup Setting section (like AWS/GCP).
Now the documentation says that AWS, Azure, and GCP instances should all have that activate button – but in my demo that is clearly not the case. Sounds like I’m going to be opening up a ticket. In the mean time I recommend making sure this enabled when you create an instance.
Should you use Cloud Backup Service?
Let me break this down into two groups, Cloud Volumes ONTAP instances and on-prem clusters.
For CVO instances, protecting your data from loss is a shared responsibility between you and your cloud provider. However most of the onus falls on you. AWS/Azure/GCP could outright lose a CVO supporting volume at any point and time, something completely out of your control. While I haven’t heard of issues in GCP or Azure *knock on wood*, I have heard of AWS EBS volumes just going MIA and Amazon coming back and saying ‘Sorry, not sorry, hope you had a backup.’
Thus for best practices you’re always going to want a second copy of that data. Here you have top options, either use Cloud Backup and have an offline copy you can restore from, or have an online copy via another CVO instance you’re replicating to. Which direction you go will be based on SLA requirements* and cost**.
* In my testing, Cloud Backup restores are pretty quick. But if you lose an underlaying volume in a CVO instance you’ll probably have to setup a new instance and do whatever configuration you need to do to make the data application accessible. Compare this to a SnapMirror’d copy on another instance which can be standing by in a warm state ready to go.
**CVO comes with a NetApp license cost, plus cloud provider costs for running the instance’s compute and storage. Compare that to the cost per GB of your volume backups. I haven’t done the math yet but I reckon it’s lower.
Now for on-prem systems, consider that having a second copy of your data has long been a best practice here as well. When considering Cloud Backup Service you need to consider not only the SLA, but the restore methodology. The current limitation of volume only restores, and that you can only restore to a CVO instance, is one hell of a limitation.
Update! – Jan 29 2021 – As of Jan 11, 2021 cloud backup now supports single file restores via browsable file catalog, but only for Cloud Volumes ONTAP and on-prem ONTAP. As I understand it you restore individual files from on-prem backups back to on-prem volumes. I’ve also been told that volume level restores to on-prem systems is supposed to be available within the next month or two. No word on Azure or Google Cloud for these features.
If you need a quick and easy way to get an offsite backup with as little infrastructure investment then I think it’s a great option. Same if you want to build a disaster recovery strategy around it.
At the end of the day I think Cloud Backup Service, as confusing and limiting as it is, can provide a strong value to a number of infrastructure types. Just be aware of its limitations. The lead, which NetApp sort of buried, is SnapMirror Cloud. I think we’ll see a lot more backup providers adding that functionality to their products and revolutionizing traditional backup strategies.
Additional Reading
- Cloud Manager’s Backup to Cloud/Cloud Backup Service documentation
- A New Backup Architecture – SnapDiff V3 (a NetApp article by Ling Zheng discussing SnapDiff and SnapMirror to Cloud)
Change Log
- 1/29/21 – Added info about supported restore types & methods
- 2/3/21 – Added Druva to the list of supported third party products, and note of CommVault future support. Add a bit on supported CBS object targets, encryption, and licensing.